

Au cours des dernières années, les plateformes ont restreint l’accès à leurs données pour de multiples raisons : optimisation des infrastructures, sécurité, respect de la confidentialité des données privées ou valorisation de leurs modèles d’affaires. Du point de vue de la recherche, cet accès limité aux données pose de nombreuses questions d’ordre méthodologique pour les études qui s’appuient sur des corpus constitués de publications social media. Premièrement, Facebook autorise l’accès aux données qu’il accepte de partager avec le marché ; ce sont notamment les publications de pages dites « publiques » qui ne représentent qu’une minorité de l’activité de la plateforme et de ses interactions entre usagers. Toutes les publications sur les profils d’usagers et les échanges via les outils de messagerie, c’est-à-dire la majorité des interactions – et probablement les plus intéressantes à analyser pour les marques qui cherchent à comprendre les comportements de leurs consommateurs, sont occultées. Depuis plusieurs années, les praticiens utilisent l’API Graph de Facebook permettant de collecter des données historiques sur les pages. C’est un outil plébiscité par les marques, le plus souvent au travers de solutions SaaS, pour évaluer leur présence sur le réseau, questionner leurs investissements ou produire des connaissances marketing. Cependant, Facebook décide aussi des modalités d’accès aux données de sa plateforme (quota, type de requêtes possibles…) façonnant ainsi les méthodologies et les outils, non pas en fonction des données nécessaires et utiles pour les acteurs du marché mais, plutôt en fonction de ce qu’il est possible et autorisé de faire. Ces limites dessinent la faiblesse des outils disponibles au service de la connaissance marketing sur Facebook ; c’est ainsi que les acteurs du social listening concentrent leurs offres sur l’analyse d’autres plateformes. Dans cet univers des possibles, les marques ont compris que les données capturées sur les plateformes s’éloignent du régime de représentativité des études traditionnelles, elles ont construit des méthodologies d’analyse qui s’appuient essentiellement sur l’exhaustivité des jeux de données. Or, Facebook limite aussi l’accès aux données en sélectionnant – sans que l’on sache vraiment selon quels critères – les publications les plus pertinentes. Autrement dit, l’API Graph de Facebook ne retourne pas toujours l’intégralité des publications effectuées par une page et, dans le même temps, la majorité des usagers de ces outils s’appuient probablement sur des jeux de données tronqués…
Nous illustrons cela avec un cas d’usage courant au sein des directions de la communication ou du marketing qui souhaitent réaliser un benchmark ou un reporting en capturant des publications de pages Facebook dont elles ne sont pas administratrices, sur une période passée. Nous avons sélectionné 16 pages Facebook de médias francophones considérés comme des contributeurs actifs, publiant fréquemment avec une certaine régularité tout au long de l’année. Nous cherchons à capturer l’exhaustivité de leurs publications effectuées en février, en adoptant trois stratégies de collecte :
- Un scénario usuel : l’outil effectue une seule requête par page pour la totalité de la période. Notre collecte est lancée le 1er mai pour récupérer les données historiques du 1er au 28 février. C’est cette méthode qui est le plus fréquemment utilisée par les outils SaaS.
- Un scénario plus consommateur en requêtes API : l’outil effectue cette fois-ci une requête par page et par jour. La collecte est lancée le 1er mai et on récupère à rebours les données du 28 février, puis du 27, puis du 26, etc. pour chacun de nos médias.
- Un scénario conçu par The Metrics Factory : nous récupérons les données au fil de l’eau, jour après jour. La capture des données débute le 1er février à minuit et nous récupérons chaque jour les données de la veille. Bref, nous capturons des données historiques, mais sur une période récente.
Les limites d’accès aux données évoquées précédemment sont sans équivoque. Nos deux premiers scénarios ont retourné respectivement 3677 et 3672 posts, tandis que la méthodologie conçue par The Metrics Factory a capturé 22.011 posts, soit 6x plus de données collectées avec cette méthode ! Les données capturées par les deux premières méthodes sont quasi-identiques, et il est difficile de comprendre pourquoi Facebook ne retourne pas exactement les mêmes publications. Néanmoins, le scénario n°2 est clairement moins performant car plus consommateur en requêtes APIs (16 pages x 28 jours = 448 requêtes a minima), ce qui implique des temps de traitement plus long (~1h30 vs 3min) afin de respecter les quotas imposés par Facebook (200 requêtes par heure).
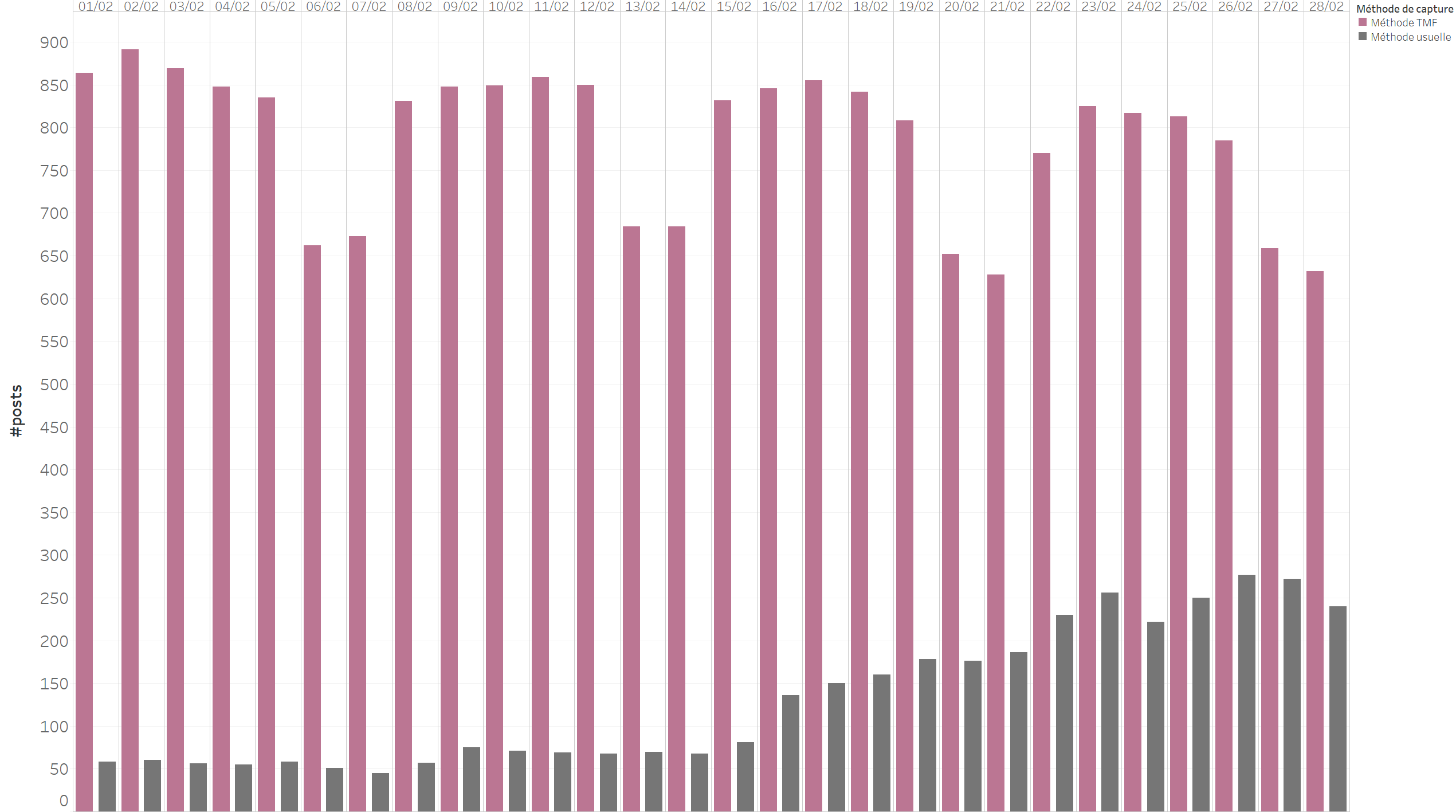
Les données retournées par la méthodologie conçue par The Metrics Factory dessinent un tout autre motif que celles des deux autres approches. Les publications effectuées par les médias sont régulières, et présentent une forte saisonnalité avec des pics d’activité les jours ouvrés et des creux le week-end. A l’inverse, les données collectées par la méthode usuelle dévoilent la sélection des posts effectuée par Facebook : environ 35% des publications sont retournées les premiers jours, puis le volume s’estompe à environ 5% pour les posts plus anciens.
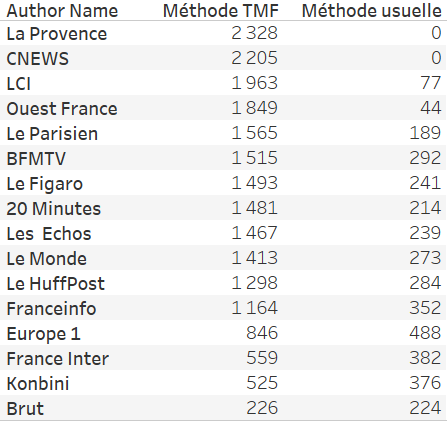
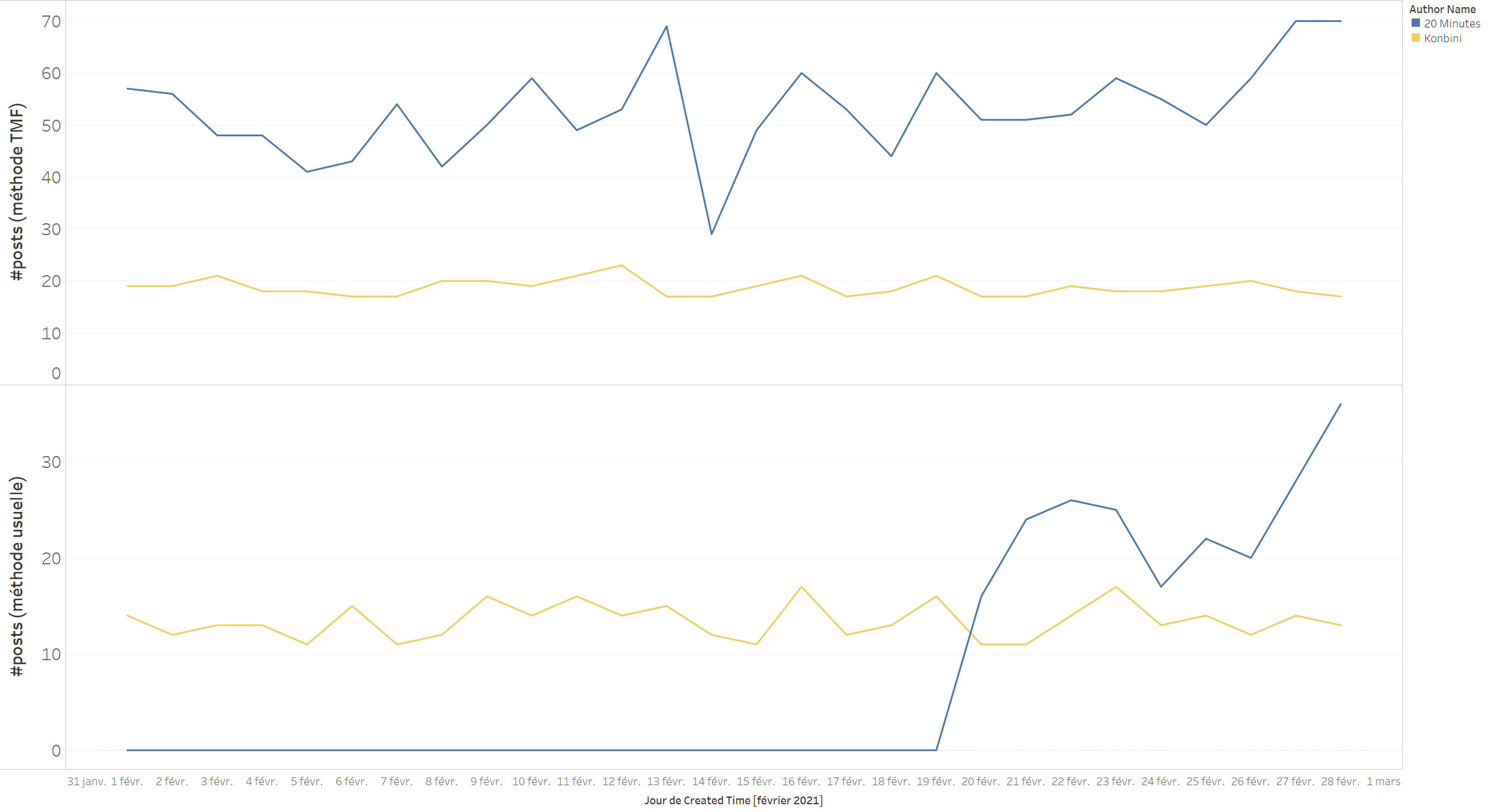
Pire encore, les pages les plus actives sont représentées de façon minoritaire dans les résultats de la première collecte. Avec la méthode The Metrics Factory, nous avons pu récupérer 2328 posts publiés par La Provence entre le 1er et le 28 février tandis qu’avec la méthode usuelle, aucun post n’a été retourné. Il devient donc impossible de récupérer des données historiques pour des pages au-delà d’un certain temps… C’est ce que nous pouvons constater dans le graphe ci-dessous : Konbini publie relativement peu comparativement à 20 minutes, nous avons pu capturer des posts pour toute la période. En revanche, pour 20 minutes, l’API ne retourne plus d’informations après 9 jours.
Le plus étonnant reste la méthode de sélection des publications : l’API ne retourne pas les posts présentant le plus d’engagements. La méthode usuelle de collecte (scénario n°1) ne retourne sur la période que 28% du total d’engagements. Par exemple, ce post de BFM TV (115k engagements – 3e post cumulant le plus d’engagements sur la période), ces images d’un ministre suscitant la polémique (60k engagements) ou cette actualité plus récente (11k engagements) n’ont pas été capturé avec la méthode usuelle.
Les points à retenir :
- Les plateformes limitent l’accès à leurs données, mais aussi les modalités de cet accès.
- Cet accès limité pose des questions d’ordre méthodologique et façonne les outils de marché en fonction des conditions d’accès à la donnée
- L’exhaustivité des données n’est jamais garantie, dès lors que les plateformes sélectionnent ce qui peut être collecté.
- Sans tiers de confiance, la qualité des données n’est pas non plus garantie : les données collectées proviennent directement de la plateforme, sans certificat de leur intégrité.
- L’interprétation des données est d’autant plus difficile que les critères de sélection des données retournées ne sont pas connus.


